Visual Informative Part Attention Framework for Transformer-based Referring Image Segmentation
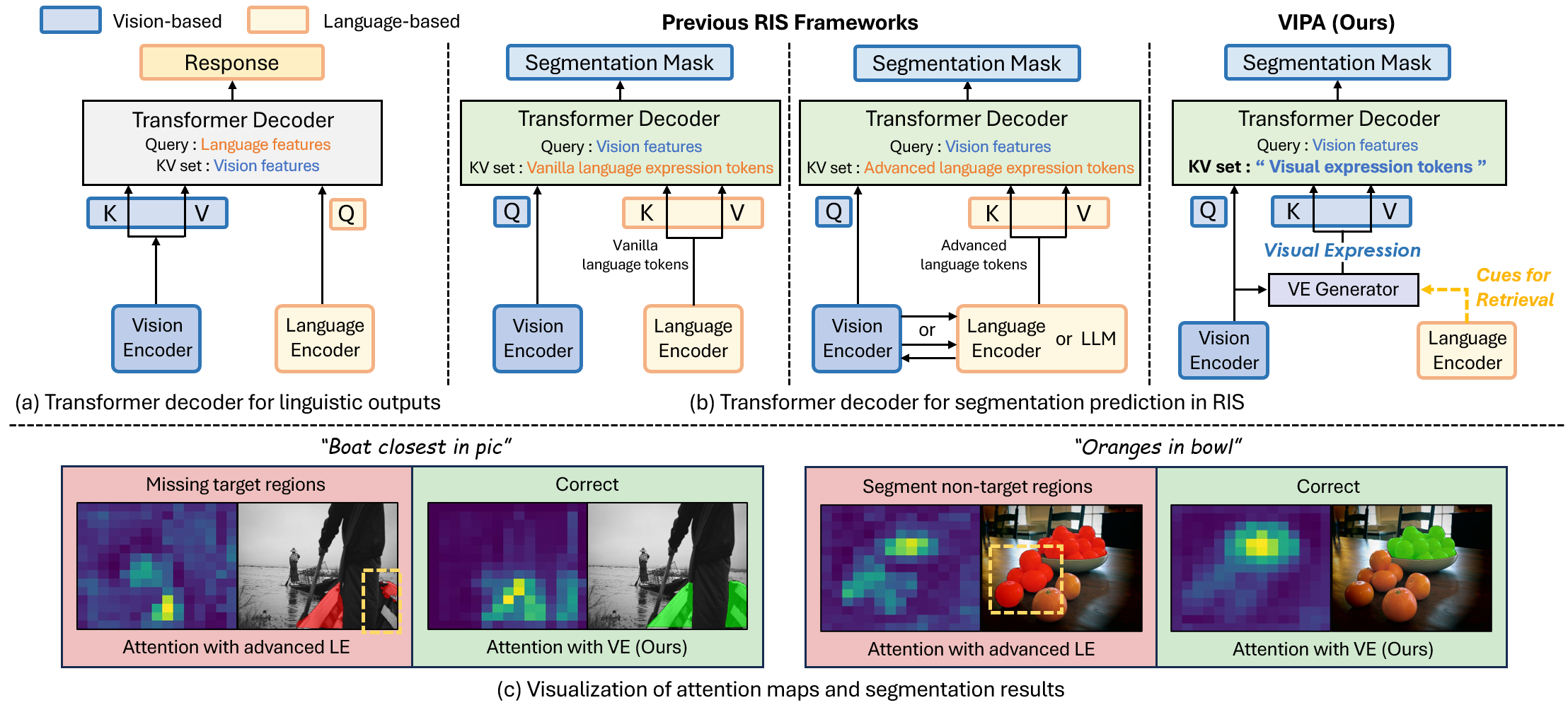
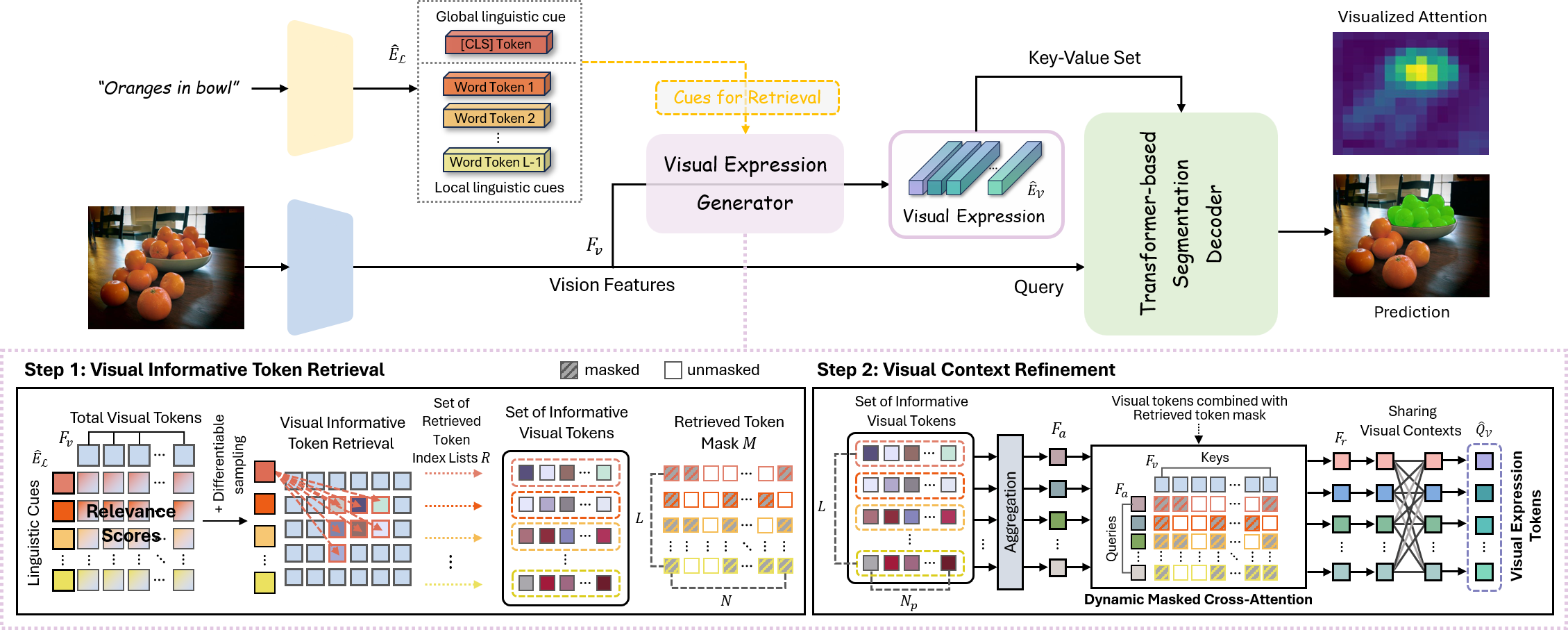
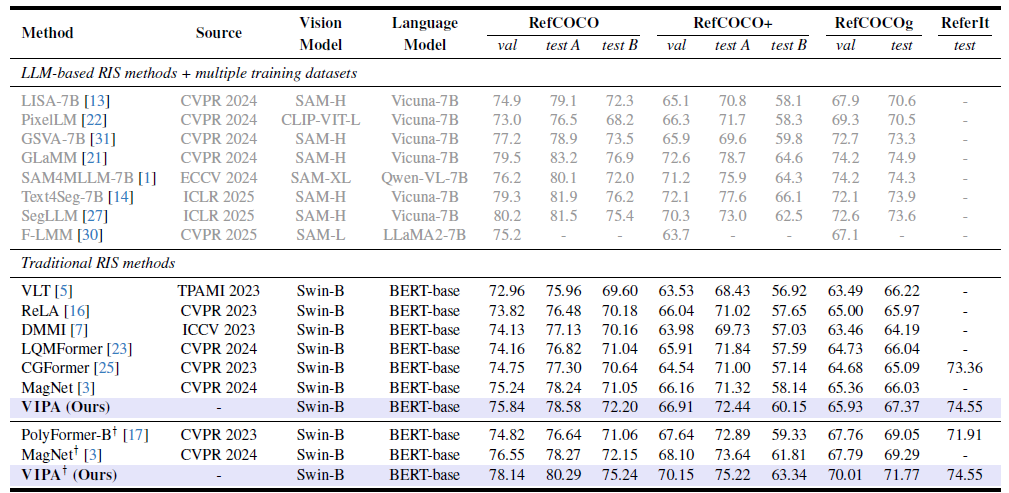
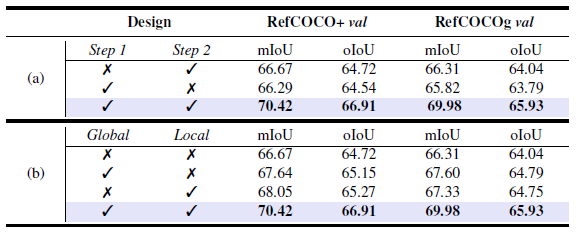
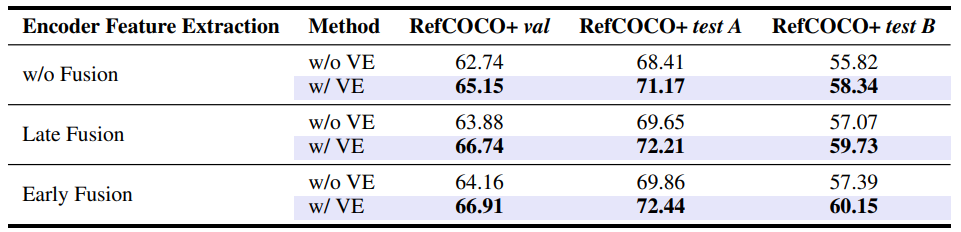
Figure 1. (a) Example of a transformer decoder used to extract language outputs. (b) Illustration of different RIS frameworks. Different from previous works, our approach leverages \textit{visual expression}, generated from the retrieved informative parts of visual contexts, as a key-value set in the Transformer-based segmentation decoder. (c) Visual comparison of two different key-value sets. Yellow dotted boxes are incorrect predictions. The visual expression (VE) robustly guides the network's attention to the regions of interest, whereas the advanced language expression (LE) shows incomplete prediction.